Essay · Data & Analysis
F1 Prediction: An Honest Attempt to Beat the Market
A Monte-Carlo race simulator, a strategy optimiser, and a fully documented failure to find a betting edge. The negative results are the point.
Most "F1 prediction" projects claim 98% accuracy and quietly leak the answer into the training data. I wanted to know something harder: can you actually beat the F1 betting market? The short answer is no. The longer answer is more interesting, and this is the project that proves it rather than hiding it. The live app is at f1.built-by-bobby.com.
What it is
A race-prediction and strategy engine built like a real quant study: pre-registered, forward-chained, leak-free. A mechanistic Monte-Carlo simulator runs each race ten thousand times with per-circuit tyre, fuel and safety-car models and a hazard model for retirements, and reports a finishing-position distribution instead of a single guess. A strategy lab works the pit calls, undercut, overcut, cover or extend. And a markets tab scores all of it against reality with calibration backtests and the live Polymarket line.
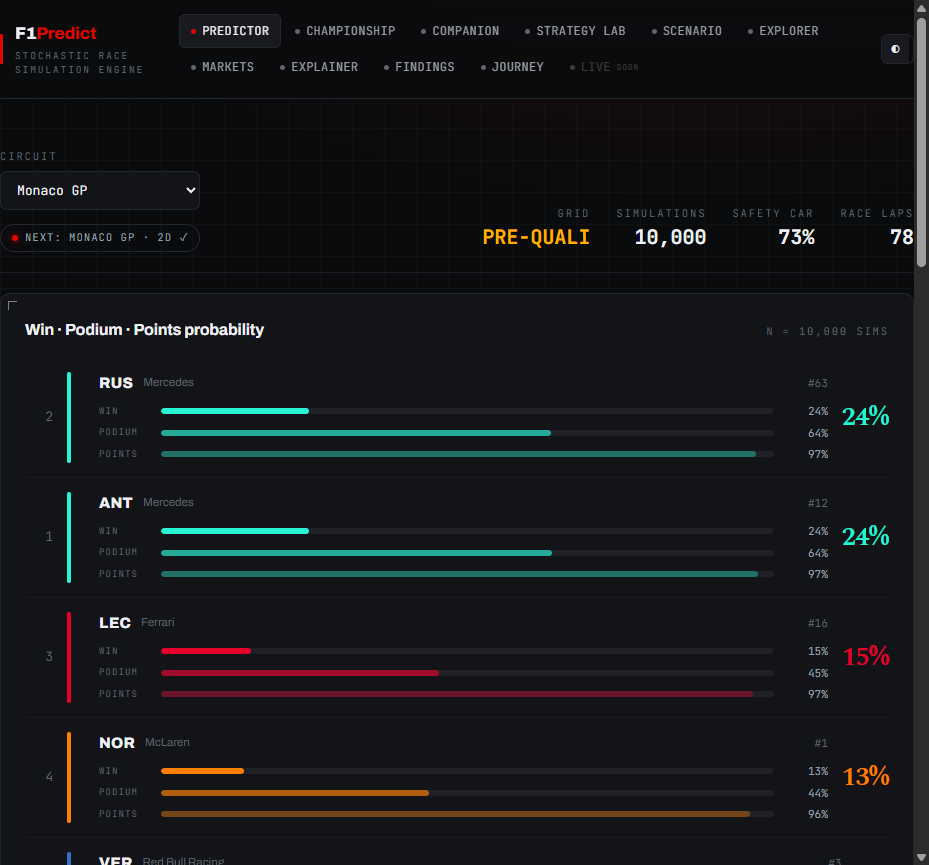
The predictor. Ten thousand simulated Monacos collapsed into win, podium and points probabilities per driver.
The honest part: it does not beat the market
I ran a model bake-off: a ten-line grid-and-qualifying baseline, a PL-Glicko rating system, a Kalman pace filter, and LightGBM. They all clustered around the same accuracy, and none of them meaningfully beat the ten-line baseline. The signal is the grid. Everything fancy on top is rounding error.
Against the betting market it is worse, in the honest sense. The pre-race outright market is efficient, roughly 0.95 correlated with anything I could build, and it is already sharp twelve hours out, the moment qualifying ends. The in-play win-probability model is well calibrated, but on a proper detrended lead-lag test it does not lead Polymarket. The edge I thought I had was just two markets converging on the same truth at the same time. Cleanly killed. And market-making those contracts as a retail maker is negative expected value once you decode the fee and rewards maths.
What actually holds up
Two things survived. The calibration is genuinely good: when the model says 24%, it happens about 24% of the time, which is the whole game and harder than it sounds. And the strategy tooling is interpretable, the anti-black-box, showing its working on every pit call rather than emitting a number and asking you to trust it. That is the part worth keeping. The fifteen short research briefs documenting the dead ends are, honestly, the most useful thing in the repo.
Built to stay alive
It is a live app that auto-updates after each race weekend, but every live path fails safe. If a data feed changes shape, or the season is over, the markets tab serves the last good snapshot, labelled and timestamped, instead of erroring. The post-race refresh runs as a scheduled job that only commits new data when the tests pass, so a bad week commits nothing and the app keeps serving last-good data. The boring infrastructure is the point: data apps rot when their live features are brittle.